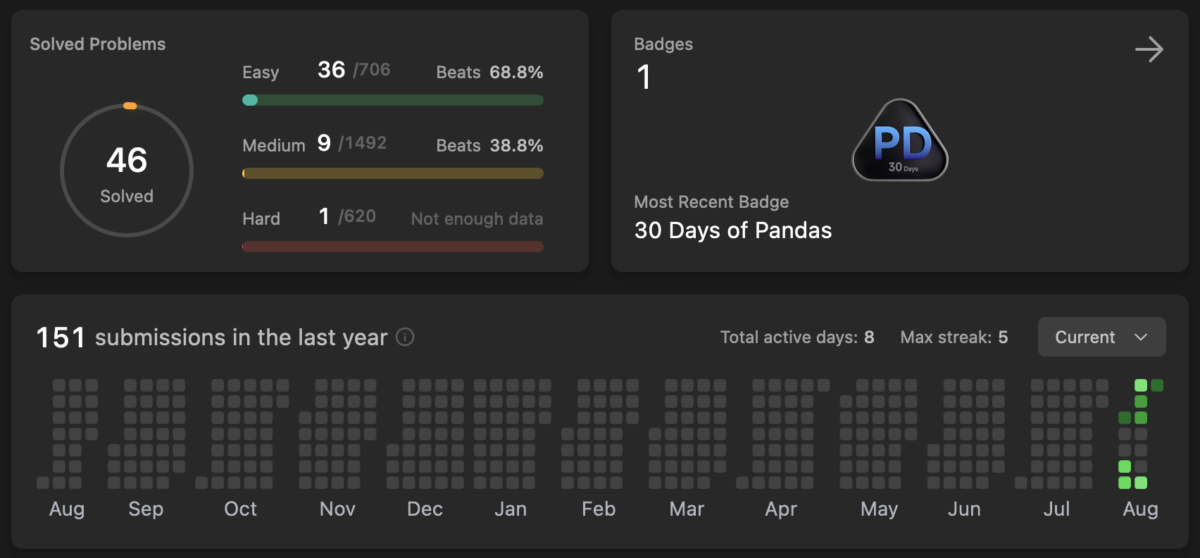
Over the last decade I seem to have been working in environments, where many engineers and engineering minded people spend time with programming puzzles and coding challenges. Let it be Advent of Code, Project Euler, Exercism, TopCoder, or Leetcode. I’ve tried all of these before (and probably a few more that I no longer remember), though with various amount of time spent all fired up, and then fizzled out. Recently I’ve picked up Leetcode, since from the above list that’s why I’ve spent the least amount of time with and others mentioned using it a way to relax and learn on weekends (suspend judgement on the wisdom of that for now).
Thus in the last two weeks I was solving problems, though not just any problems, but went in mostly for the Easy ones. These few dozen problems and short amount of time doesn’t give me a deep impression, but from past experiences I can still distill some lessons that help shaping future experiments.
The purpose of using the Easy problems is different from e.g. going all in for puzzle-solving fun, which is likely in the Hard ones. Rather than that, I think easy problems can be used for learning some new techniques, looking for common patterns, and becoming more polygot.