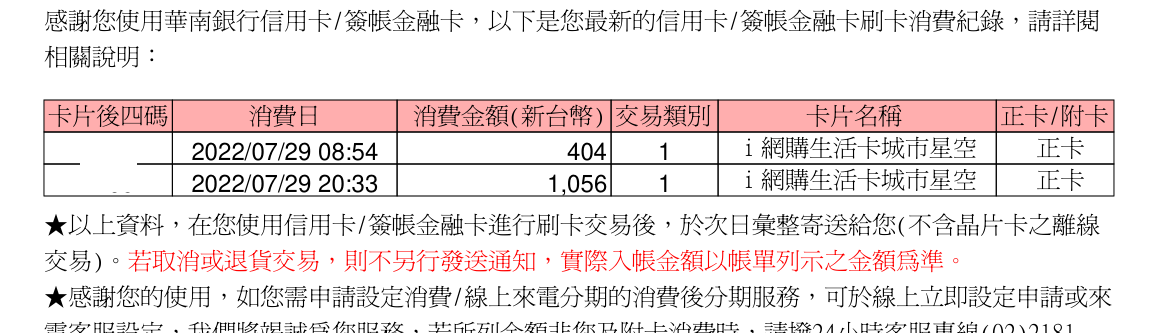
I had received a (family) project brief recently. In Taiwan many credit/debit cards have various promotions and deal, and many of them depend on one’s monthly spending, for example “below X NTD spending each month, get Y% cashback”. People also have a lot of different cards, so playing these off each other can be nice pocket change, but have to keep an eye on whether where one is compared to the max limit (X). So the project comes from here: easy/easier tracking of where one specific card’s spending is within the monthly period. That doesn’t sound too difficult, right? Except the options for these are:
- A banking website with CAPTCHAs and no programmatic access
- An email received each day with an password-protected PDF containing the last day’s transactions in a table
Neither of these are fully appetizing to tackle, but both are similar to bits that I do at #dayjob, but 2. was a bit closer to what I’ve been doing recently, so that’s where I landed. That is:
- Forward the received email (the email provider does it)
- Receive it in some compute environment
- Decrypt the PDF
- Extract the transaction data table
- Clean and process the tabular data
- Put raw in some data warehouse
- Transform data to get the right aggregation
- …
- Literally profit?
I was surprised how quick this actually worked out in the end (if “half a weekend” is quick), and indeed this can be a first piece of a “personal finance data warehouse”.
Technical implementation
I wanted to have the final setup run in “The Cloud”, as that’s one less thing to worry about. The most obvious arrangement, based on past experiences was combing AWS Simple Email Service (SES) to receive an email, and a Lambda to run serverless processing. On the data warehouse side the real obvious choice is GCP’s BigQuery, however, so I looked into what would be a similar arrangement for the processing pieces if I want to put everything into a single cloud provider.
After some docs diving the most natural arrangement on GCP seemed to be quite different: an App Engine deployment with Mail API enabled. This gives a receiving domain name (@[Cloud-Project-ID].appspotmail.com) , and every email sent there is just passed to the server that is running in App Engine. This seemed pretty simple! App Engine also has a free tier, though that comes with pretty small memory limits, which features in this story too.
The final result of the server part is shared on GitHub, and should be easy to reuse or extend.
PDF processing
Getting the attachments out of the email was pretty straightforward with the Mail API, so the first heavier task was opening the encrypted PDF and getting the table out of it. Opening PDFs are quite common, but the table extraction was a bit of a journey.
False try
First I was searching around (as anyone else does) for someone else’s rundown of the options, as an example. From there I honed in on pikepdf to open the password-protected files, an tabula-py which seemed handy to extract tables right into Pandas DataFrames. One subtlety was that tabula-py is just a wrapper around tabula-java to do the extraction, and needs a Java environment installed. The free tier of App Engine uses their standard environment where all I have is my code and “requirements.txt” to install my python dependencies, so it’s obvious how would I get Java into the deployment correctly.
Enter the scene install-jdk which can install the Java environment at runtime. That was sufficiently crazy hack to actually work, and it did work. Or so it seemed, since the data was processed and showing up in BigQuery, when I’ve sent test emails into the system.
Upon closer inspection, though, there were loads of duplicate lines. Between signing off in the evening, and checking it in the morning, I had bunches of them, and were still coming in…
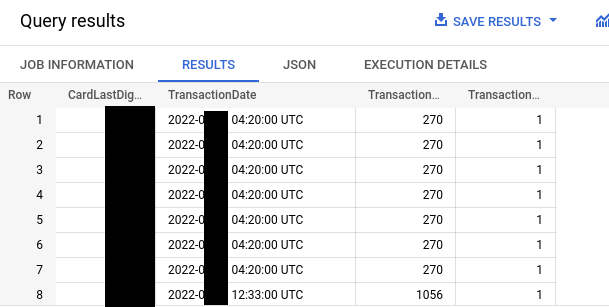
I should have checked the logs earlier, because once dig in, there were bunches of “server errors” listed that didn’t connect to any programming errors that I might have made, rather than (here comes the epiphany) instances being killed for being out of memory / blowing their memory budget (of 256MB for the free tier). Thus what happened is:
- the Java run of tabula was just using too much memory while processing the PDFs
- it finished processing and like loaded the data but it takes a bit of time
- GCP catches up and kills the instance while that is still going on, and reports to the Mail API that the email hasn’t been properly handled (server error during that process)
- Whatever is handling the incoming email queue in GCP will just just keep the data and retries later
- The cycle repeats…
This didn’t seem very helpful and the repeat emails were piling up in whatever (opaque, to me) system GCP has, so needed a quick replace of tabulate with something lighter…
Worse is better and actually good
Going down the list of recommended libraries, next I looked at camelot-py which looks great, but needs OpenCV on the machine to do its work, so back to the “how to install OS packages on Standard AppEngine?” question. For some extra inspiration I was looking at camelot’s comparison with other similar tools page and it was a bit disappointing (though not surprising) that pretty much every other library is “worse” on various PDFs compared to camelot. Just for kicks I did try some out, and pdfplumber actually delivered:
- it does actually work on the example PDFs I had from previous bank emails
- nothing else beside pip install
- it can actually handle decrypting the PDF as well, so helper libraries can be dropped
- the extracted data is in Python tables, but it’s just an extra line to get DataFrames, so no sweat
- The extracted data was actually better quality than tabula’s, so had to do fewer cleanup steps!
This was a pure win, and indeed it’s worth looking stuff that works with the data at hand, not ignoring the edge cases, but also not overly emphasizing being able to do “everything” when there’s a clear target of what “thing” needs to work. (Potential technical debt considered too).
Data transformations and visibility
Now the data sits in BigQuery properly:
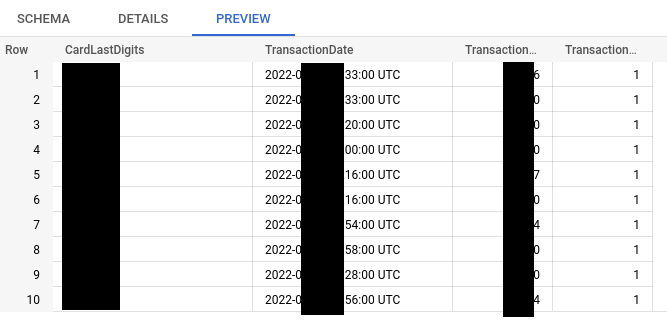
The raw transaction data loaded into BigQuery was the first step, but still need to answer the question: in this billing period, how much have I spent?
Not being a data analyst (or not yet?:), this took a bit of figuring out. As other novices share their bit of “clever code” when it’s actually trivial to the experts, I’m sharing here the bit of SQL queries in a similar “that was fun to figure out, wasn’t it?” way. I’m sure it can be much improved, but it’s a good reminder for myself as well.
Given that my billing period starts on the 23rd of the month, get the aggregated value of transactions for each billing period:
WITH
Aggregated AS (
SELECT
DATE(TransactionDate, 'Asia/Taipei') AS day,
TransactionAmountNTD
FROM
`personal-data-warehouse.finance.huanan` ),
calendar AS (
SELECT
day,
-- Find the last day before the new interval
DATE_SUB(
DATE_ADD(
day,
INTERVAL 1 Month),
INTERVAL 1 DAY
) AS endday
FROM
UNNEST (
GENERATE_DATE_ARRAY(
-- Start date in the past before any data,
-- on the right day of the month for
-- the billing cycle.
'2022-05-23',
CURRENT_DATE('Asia/Taipei'),
INTERVAL 1 Month
)
) AS day
) SELECT
SUM(TransactionAmountNTD) AS `MonthlyTransactions`,
COUNT(*) AS `TransactionCount`,
EXTRACT(Year FROM c.day) AS `Year`,
EXTRACT(Month FROM c.day) AS `Month`,
FORMAT('%d-%02d', EXTRACT(Year
FROM
c.day), EXTRACT(Month
FROM
c.day)
) AS `Interval`
FROM
calendar AS c
JOIN
Aggregated AS a
ON
a.day BETWEEN c.day AND c.endday
GROUP BY
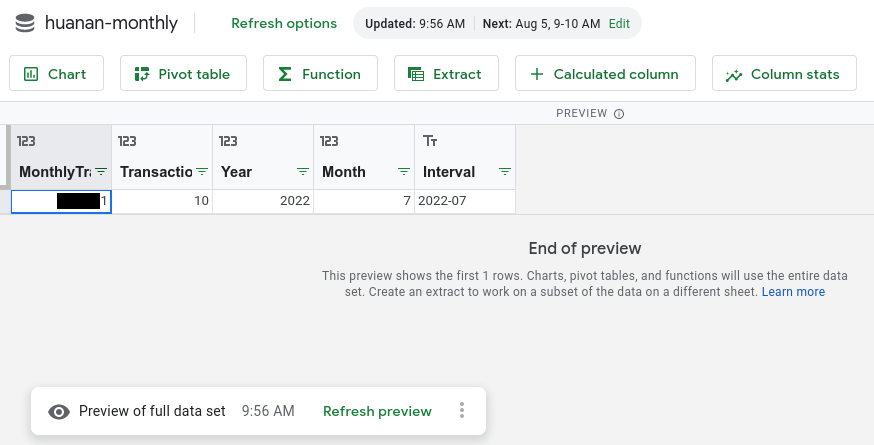
c.dayGood stuff on the date array and joining with a “between” statement, those are the main TIL. They also already came up at #dayjob, which was very satisfying.
From here the data I surface in a connected Google Sheet which is pretty practical, though leaves the “being notified when I approach/reach X” out, but that’s fine for now.
Testing and getting to “production”
One good thing about personal projects is that I can make them as “good” as I want to (or as “bad”, of course), which usually results in an unhealthy amount of tweaking, trying out various best practices to see if they work, and so on. Here I really wanted to get the system well tested, for example, which turned out to take loads more time than actually writing the original service. Actually, there’s nothing surprising about that for software engineering professionals, but still can catch people off-guard.
Here the tricky parts came from two areas: FastAPI settings and cloud service integrations.
The former is always a bit of an issue, depending on how the code uses the settings (whether things can be patched well at testing time), but here I also used a trick for the server to pull the PDF decryption key from Secret Manager, so I don’t have to deploy environment files, nor keep settings like that in version control, etc… But this meant a trickier flow of getting the FastAPI testing client up in a way that it worked without it talking to the cloud backends (and stalling, and failing…). Nothing that some good mocking cannot solve (says the person with hindsight).
For the cloud services part it meant mocking BigQuery connections, so that the test can actually pretend to “receive” an email all the way looking at the “database” and see the right information being there. Under the hood I’m using pandas-gbq, and thus it was interesting to look under the hood for their tests, borrowing some of them. Took a bit more time, but that’s working pretty well now. Still need to do some extra bits and pieces to do cover more of the workflow, but I’m already more confident about things working. Also, all this will be very useful on other projects that are interacting with BigQuery in any way (not just through Pandas).
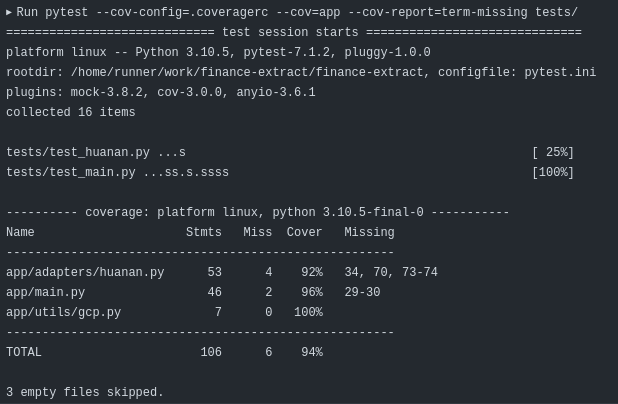
Big evergreen lesson on testing: you have to write your code to be testable. Lots of code out there is not even not tested, but it’s even extremely difficult to actually test. This needs remembering in every development. Also, test writing never really stops, there’s always more thing to test for. And finally, can always try more advanced testing, such as using automated test case generation (e.g with hypothesis), and fuzz testing (e.g. with pythonfuzz). The next frontier, right after I’ve implemented the currently skipped tests. And finally, remember that code coverage is not case coverage, so the goals should be maximizing the latter, while the former is just a potential proxy for it.
Future outlook
It would be nice to take this idea of financial data analysis further and add some actual dashboard (say deploying Superset somewhere which is excellent for this). It would help to get more information into the system as well, though, currently it’s very sparse. That would mean adding other financial sources, maybe if finding an API in the end, or doing a bit of “pragmatic execution” and do a CAPTCHA bypass (since I quickly checked that my credit card provider’s CAPTCHA is completely readable by Tesseract, for example, so I could likely scrape things there if I really wanted.
I’m not holding my breath for having something like UK’s Open Banking here which enables apps like Emma so all this is accessible for people who don’t want to code. But where’s the fun in that (for me)? :) (In fact there’s a lot of fun in open access APIs, so this would be the real way of doing it…)
Finally, it’s good to remember how easy it is to corrupt “production” data sets, but also with the right tools (like snapshots), some of that pressure can be less. There are always bugs, the question is how to mitigate their effect.