Once in a decade or so the time comes to install (or reinstall) my personal computer. This time the occasion is getting a new laptop, something more modern, something more capable. The time passed and the changes in technology since the last time I had to do this means that the installation is likely familiar, but still different – sometimes subtly, sometimes in unrecognisable ways.
Setting up my laptop is now in its 3rd day, and the experience made me think of incremental games. Incrementals1 are where you make some progress in gathering some resource, then have to reset your progress that gives you some small buff or gain. You then start again – but better. The cycle repeats and you might have the same experiences countless times, but after a while the game can be much faster or even unrecognisable due to the accumulated effects.
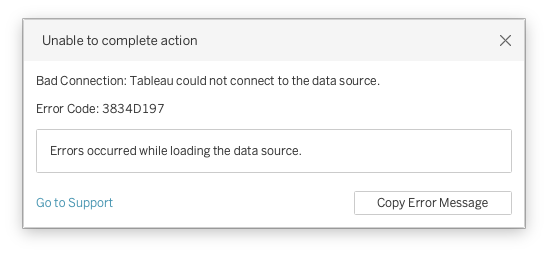
While I was installing Arch Linux this time I went through the following cycle:
- Partitioned my disk and installed the system, but then couldn’t boot into it
- Redo the partitioning, system, and bootloader install, now I can boot into it, but don’t have any network access
- Redo the system config, now I have network access, but have to figure out what desktop environment am I going to run, and what do I need for that. A hot mess ensues after trying out all main desktop environments for kicks
- Reinstall the system, cleaner, with my desktop environment of choice, now the high resolution environment makes everything either: tiny, gigantic, and/or blurred.
- Sorted out most of the sizes of things, have network, have Bluetooth, but the sound and the media buttons don’t work
- Sorted out sound, now the power management locks me out while watching a video….
… and so on. I know I have a few more rounds (few more “crunches”) to do get there, and the multilingual typing input setup will be a doozie with bopomofo, but I’m getting better and feeling better every round – that’s how a good incremental game goes. A power up there, a know-how of a semi-obscure, quality of life config here2.
Of course I could have gotten an Ubuntu or Fedora image, installed everything in way less time than writing about the experience, and could already be using it — but that’s a whole different game3.
The games we choose to play show our values. On an optimistic day I feel I value increased knowledge; on more realistic days it certainly seems like procrastination. Now let’s keep this in mind when I finally have high enough level of Linux buffs that they change the game mechanics and I get to do something with my computer.