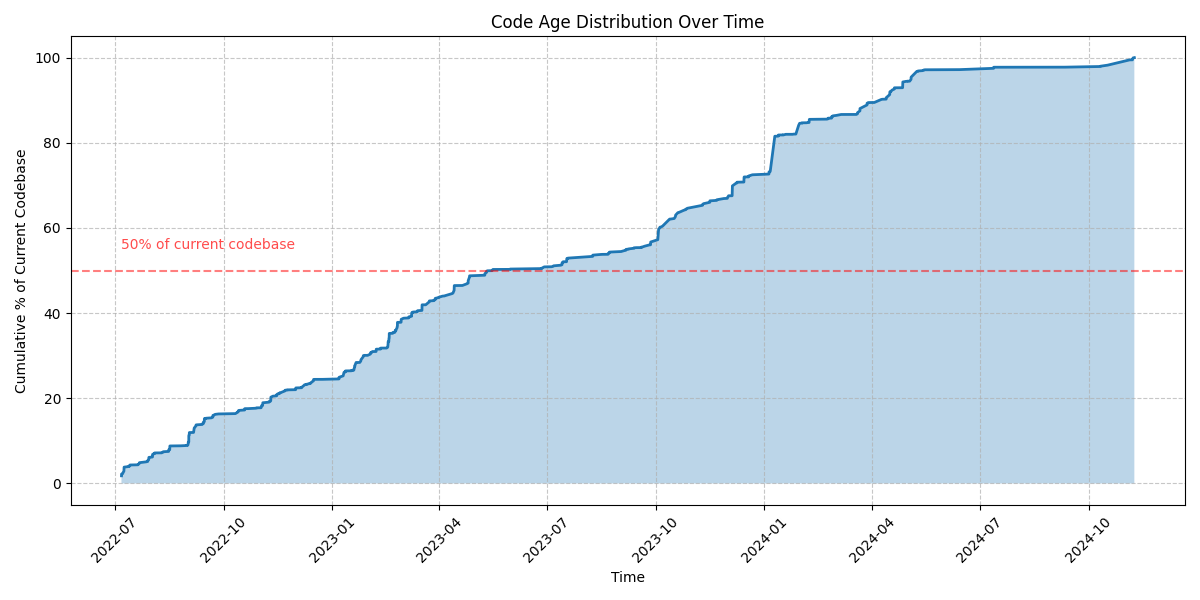
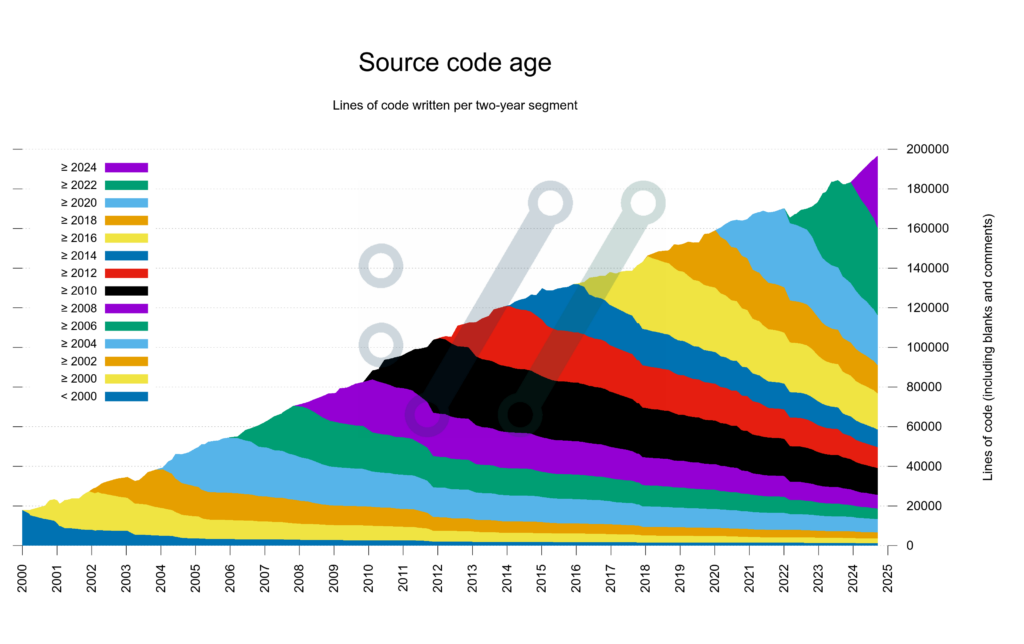
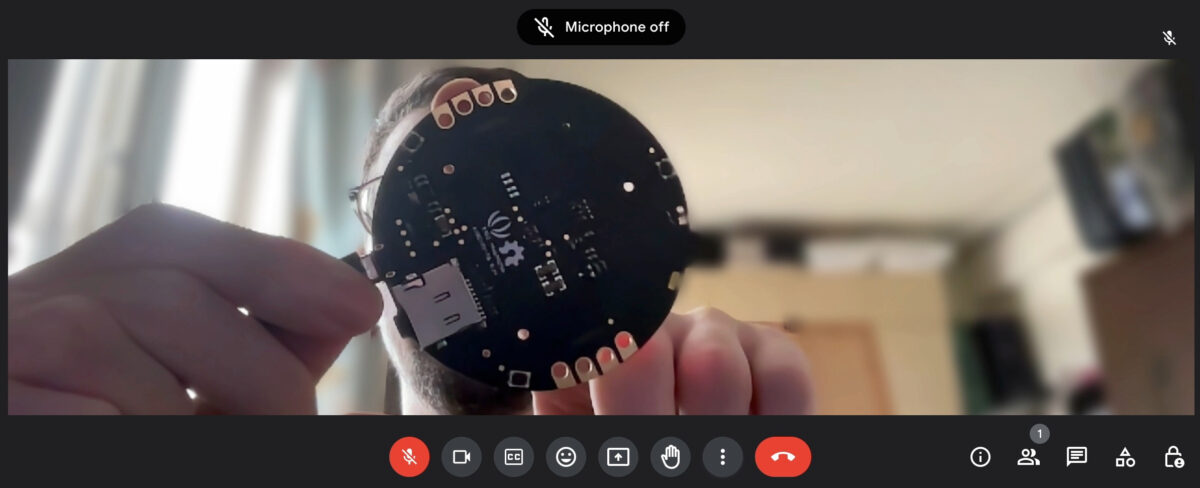
A bit like last time this post is about a bit of programmer hubris, a bit of AI, a bit of failure… Though I also took away more lessons this time about software engineering, with or without fancy tools. This is about rabbit-holing myself into an old software project that I had very little knowhow to go on…
The story starts with me rediscovering a DVB-T receiver USB stick, that I had for probably close to decade. It’s been “barnacled” by time spent in the Taiwanese climate, so I wasn’t sure if it still works, but it’s such a versatile tool, that it was worth trying to revive it.
When these receivers function, they can receive digital TV (that’s the DVB-T), but also FM radio, DAB, and also they can act as software defined radio (SDR). This last thing makes them able to receive all kinds of transitions that are immediately quite high on the fun level, in particular airplane (ADS-B transmission) and ship (AIS) tracking. Naturally, there are websites to do both if you just want to see it (for example Flightradar24 and MarineTraffic, respectively, are popular aggregators for that data but there are tons), but doing your own data collection opens doors to all kinds of other use cases.
So on I go, trying to find, what software tools people use these days to use these receivers. Mine is a pretty simple one (find out everything about it by following the “RTL-SDR” keywords wherever you like to do that :) and so I remembered there were many tools. However also time passed, I forgot most that I knew, and also there were new projects coming and going.
ADSBox
While I was searching, I found the adsbox project, that was interesting both kinda working straight out of box for me, while it was also last updated some 9 years ago, so it’s an old code base that tickles my “let’s maintain all the things!” drive…
The tool is written mostly in C, while it also hosts its own server for a web interface, for listing flights, and (back in the day) supporting things like Google Maps and Google Earth.
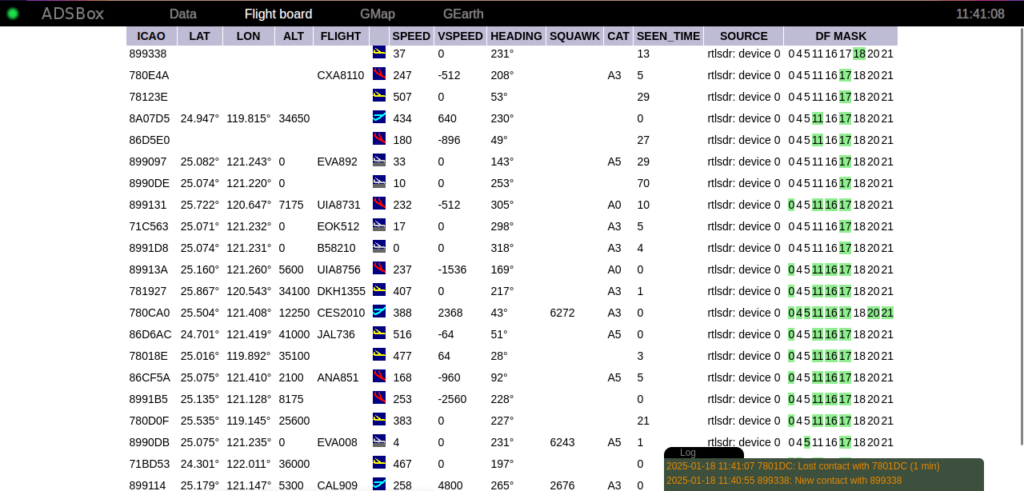
Both the Google Maps and Earth parts seem completely: Maps has changed a lot since, as I also had to update my Taiwan WWII Map Overlays project over time too (the requirement of using API keys to even load the map, changes to the JavaScript API…). Earth I haven’t tried, but I’m thinking that went the way of the dodo on the the desktop?