I have a little home server, just like mike many other geeks / nerds / programmers / technical people… It can be both useful, a learning experience, as well as a real chore; most of the time the balance is shifting between these two ends. Today I’m taking notes here on one aspect of that home server that is widely swing between those two use cases.
When I say I have a home server, that might be too generous description of the status quo: I have a pretty banged up Raspberry Pi 3B. It’s running ArchLinux ARM, the 64-bit, AAarch64 version, looking a bit more retro on the hardware front while pushing for more modernity on the software side – a mix that I find fun.
There are a handful of services running on the device — not that many, mostly limited by it’s *gulp* 1GB memory; plenty of things I’d love to run, doesn’t well co-locate in such a tiny compartment. Besides the memory, it’s also limited by storage: the Raspberry Pi runs off an SD card, and those are both fragile, and limited in size. If one wants to run a home file server, say using a handful of other SD cards lying around, to expand the available storage, that will be awkward very soon. To make that task less awkward (or replace one kind of awkward with a more interesting one), I’ve set out to set up a ZFS storage pool, using OpenZFS.
The idea
Why ZFS? In big part, to be able to credibly answer that question.
But with a single, more concrete reason: being able to build a more solid and expandable storage unit. ZFS cancombine different storage units
- in a way that combats data errors, e.g. mirroring: this addresses SD cards fragility
- in a way that data can expand across all of them in a single file system: this addresses the SD cards size limitations
This sounds great in theory and after a bit of trial-and-error, I’ve made the following setup, relying on dynamic kernel modules for support for flexibility, and a hodgepodge of drives at hand for the storage
The file system supports needs is provided by the zfs-dkms package dynamic kernel module (DKMS), which means the kernel module required for being able to manage that file system is recompiled for each new Linux kernel version as it is updated. This is handy in theory, as I can use the main kernel packages provided by the ArchLinux ARM team.
For storage, I’ve started off with two SD cards in mirror mode (going for data integrity first). Later I’ve found — and invested in — some large capacity USB sticks that bumped the storage size quite a bit. With these, the currentl ZFS pool looks like this:
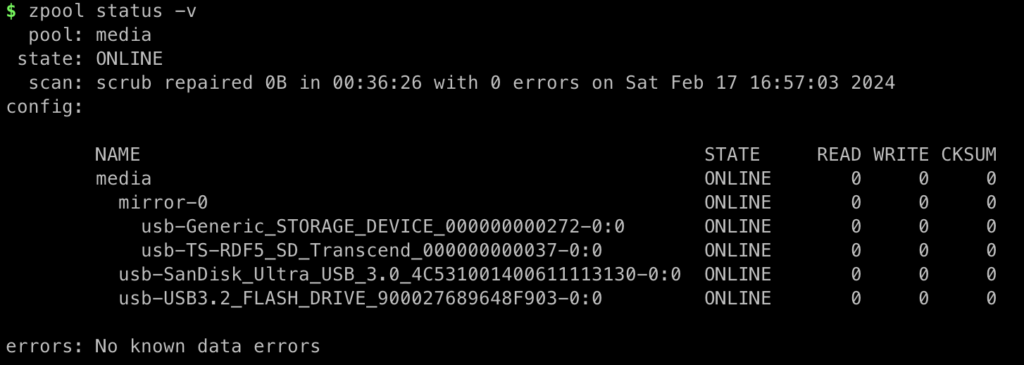
It already saved me — or rather my data — once where an SD card was acting up, though that’s par for the course. One very large benefit is that the main system card is being used less, so hopefully will last longer.
The complications
Of course, it’s never this easy… With non-mainline kernel modules and with DKMS, every update is a bit of a gamble, that can suddenly not pay off. That’s exactly what happened last year, when suddenly the module didn’t compile anymore on a new kernel version, and thus all that storage was sitting dump and inaccessible. After digging into the issue, it down to:
- the OpenZFS project being under Common Development and Distribution License (CDDL)
- the Linux kernel deliberately breaking non-GPL licensed code by starting to withold certain floating point capabilities, because “this is not expected to be disruptive to existing users”.
This wasn’t great, as user being between pretty much a rock & a hard place, even if this is a hobby and not strictly speaking a production use case on my side.
Nonetheless, it worked by downgrading to a working version and skipping updates to the kernel packages.
Then based on a suggestion, patching the zfs-dkms package (rewriting the license entry in the META file) to make it look like it’s a GPL-licensed module — which is fair game for one doing on their own machine. This is hacky, or let’s call it pragmatic.
--- META.prev 2024-02-28 08:42:21.526641154 +0800
+++ META 2024-02-28 08:42:36.435569959 +0800
@@ -4,7 +4,7 @@
Version: 2.2.3
Release: 1
Release-Tags: relext
-License: CDDL
+License: GPL
Author: OpenZFS
Linux-Maximum: 6.7
Linux-Minimum: 3.10Now, with the current 2.2.3 version, it seems like there’s an official fix-slash-workaround for being able to get the module to compile, even if it’s not a full fix. From the linked merge request message I’m not fully convinced that this is not a fragile status quo, but it’s at least front of mind – good going for wider ARM hardware usage that brings out people’s willingness to fix things!
Future development
Some while back, while working at an IoT software deploument & management company, I had a lot of interesting hardware at hand, naturally, to build things with (or wrestle with…). Nowadays I have things I best describe as spare parts, and thus loads of thingss are more fragile than they need to be, as well as gosh-it-takes-a-long-time to compile things on a Raspberry Pi 3 – making every kernel update some half-an-hour longer!
Likely the best move would be to upgrade to a (much more powerful) Raspberry Pi 5 and use an external NVMe drive, where I’d have much less need for ZFS, at least for the original reasons. It would likely be still useful for other aspects (such as snapshotting, or sending/receiving the drive data, compression, deduplication, etc…), changing the learning path away from multi-device support to the file system features.
If I wanted to use more storage in the existing system, I could also get rid of the mirrored SD cards and just just 4 large USB sticks (maybe in a RAIDZ setup), a poor-man’s NAS, I guess. Though there I’d worry a bit about using the sticks with the same sizes for this to work (unlike pooling, which has no same-size requirements), given the differences in the supposedly same sized products from different companies (likely locking me into a having the same brand and model across the board).
I also feel like I’m not using ZFS to its full potential. If I know enough just to be dangerous… maybe that’s the generalists natural habitat?