When parts of a system are strongly interconnected, one can discover latent issues while debugging something completely different. This is what happened with this blog’s caching and integrating with the Fediverse.
Fediverse adventures
I was part of The Great Twitter Exodus of 2022, and like many I’ve landed on Mastodon (hey, hello, https://fosstodon.org/@imrehg). Mastodon and the whole Fediverse and its build around the ActivityPub protocol is technically very interesting and brings back a bit of retro-joy to me (which needs some reflections on why and how is retro joyful, but another time). This current blog is running WordPress, and soon found that there’s a plugin to turn a WordPress blog into a my own ActivityPub node. That seemed some excellent way to connect up tools and make a more inter-connected Internet (besides nerding out, if I’m fully honest).
ActivityPub plugin
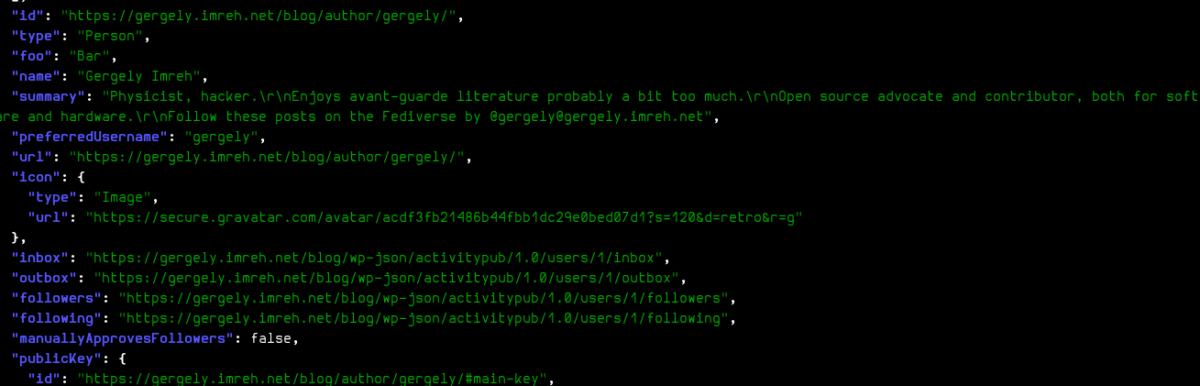
It was super easy to set up, and seemed to have worked well: take my author URL, put it your Mastodon instance’s search, and voila, there’s a compatible profile which one can follow and interact with (to an extent, but still):

It all seemed to have worked, but coming back after a while, but Site Health popped up a critical issue. 🙀
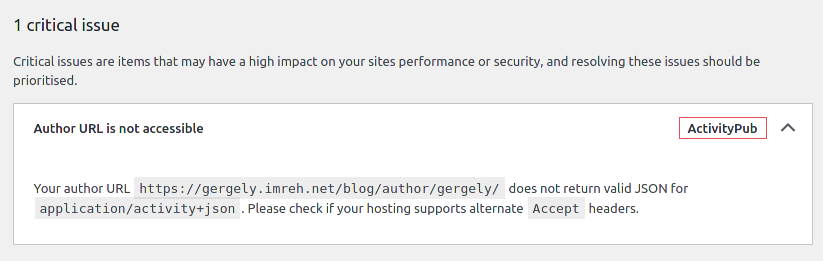
Digging in into what the endpoint actually returned when setting what response format the client want to accept:
curl --silent -H "Accept: application/activity+json" https://gergely.imreh.net/blog/author/gergely/I can see that it indeed doesn’t look like a JSON file, instead the cached web content:
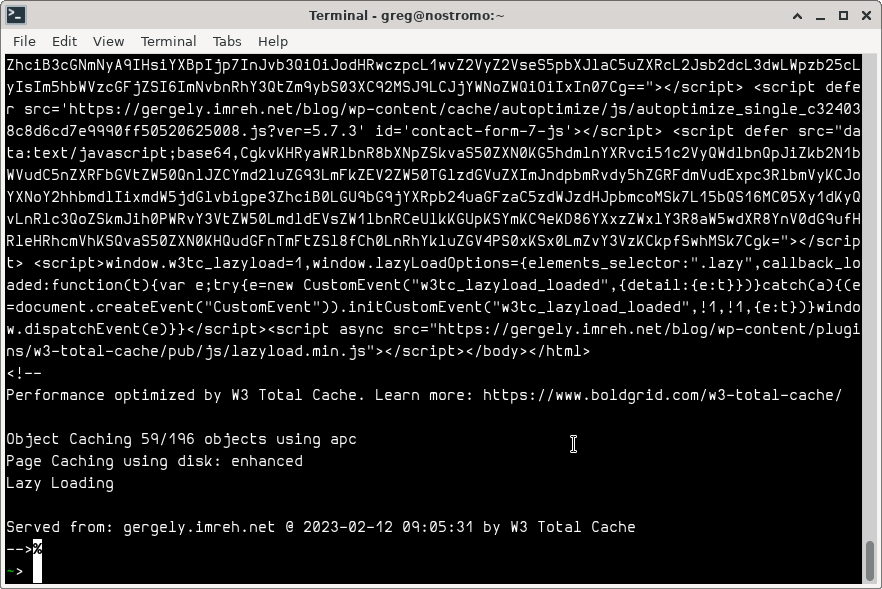
Hot on your trail, W3 Total Cache (W3TC)! I use this plugin to make this site (hopefully) more performant, but it’s not looking great in this instance. Fortunately I got some interesting pointers by asking none other the Fediverse about this issue, and got some helpful pointers.
W3 Total Cache
The way I understood how the W3TC plugin and my configuration worked was the following:
- The plugin does some internal caching (opcode, objects,…) using PHP, and something I don’t worry about much.
- The main performance benefit is coming from generating page caches on disk that can be loaded quicker then regenerating the page.
- Routing to those cached files is mostly through my nginx web server’s configuration: the caching plugin creates an nginx configuration file with the relevant logic and redirects, so on the “happy path” when the target page is cached, the request doesn’t even touch WordPress’ backend at all.
Disabling Caching for an Endpoint
Based on the above (especially point 2), my train of thought started at “Can I tell W3TC not to cache that author endpoint if a specific header is received?” Looking at the W3TC FAQs, there’s indeed a way to signal that, by disabling e.g. page caching when the plugin (ActivityPub in this case), by setting this inside the code path of the relevant page:
define('DONOTCACHEPAGE', true);Looking at the source code of the ActivityPub plugin, I could find where in the data flow one would set this, before the author template is returned. I tried it out and seemed to have worked. I’ve even opened a GitHub issue so that hopefully a fix can be developed for everyone!
Looking further in the code (to do that fix), though, it’s not only the “author” page, but silently also all the posts and the front page has the same issue (of getting cached HTML when asking for JSON). 🙀 If one disables caching on author + blogposts + frontpage, what else of note is left cached? Nothing really. And the plugin owner agrees.
Route Request Based on Headers
Let’s try instead routing the request based on headers: if a compatible “Accept” header is received, bypass the cache, and use what he endpoint returns. Here comes the issue about the 3rd point above: the nginx configuration and its use.
Ideally I would be able to add to the config a tests for this header, a check, roughly along the lines of this in nginx config::
if ( $http_accept = 'application/activity+json' ) {
# switch vars not to cache
}Following the installation steps, when Page Caching is enabled in W3TC generates an extra nginx.conf file that governs what happens. There are a lot of various checks (e.g. do not cache on POST requests, do not rewrite paths if the predicted cache file location is empty….) I’ve been following the generated file, and tried to adjust the caching behaviour. To debug, I turned to adding various headers to the response, as it was easier than messing with the nginx logging rules. For example adding this just before the last rewrite rule kicks in would show the variable’s value that would decide if a rewrite happens:
add_header X-gergely-debug "rewrite-$w3tr_rewrite";Looking at this, in every situation I was getting “no rewrite to do” outcomes, and it wasn’t in the end too much a surprise, as the logic in that file seems to be flawed: generating on disk file locations from the request incorrectly and thus never finding anything (and/or some of my misconfiguration? But there are definitely things which look plain wrong).
But while the nginx rules shrugged, in the same time my web requests were returning the files from disk! If I rewrote the generated files, I got the modified version back. Then, frustrated, even emptied out nginx.conf to try to “break” caching – and it continued to work! 🙃
So I guess the actual behaviour was different from the above 3. point, and rather:
- W3TC generates nginx rules and hope that they work and take load off the WordPress backend
- If that doesn’t fly, generate the caches internally in the plugin (of course, have to be able to do that on first requests/preloading anyways)
- The plugin still checks internally (in code) whether the cached file exists where it expects one on the disk and loads that, bypassing this above point!
I haven’t verified this yet by looking at the code, but this explains all the behaviour I’ve seen while trying things (serving files that I’ve manually changed and working while having an empty nginx rewrite).
So after all, these checks for the Accept header would need to be both in the nginx config (less important for me as it was already broken), and also in the code of W3TC (which feels currently less tractable).
Current and Future Fixes
What I’ve ended up with is the simple and dumb way for now: disable Page Caching altogether.
For my site and level of traffic that should definitely not be a serious issue, though I did check with a site speed test just in case, and I don’t see much difference for my otherwise semi-broken setup.
Still, it’s definitely a step forward not assuming & hoping things are working (ie. nginx-based chaching) when they are not.
What would be good for the future, though, is a pattern where cache plugins only cache what they can and if not pass it on to the rest of the processing (ie. check if the client “Accept” header is empty or defaults to some browser-y value). I bet this is a naive view, and there are more complications. There likely should be more complications if WordPress is more of a “platform”, given then it will have to support a lot more different use cases and behaviours.
Future Rabbitholes
I’m definitely not alone in this quest, there are others who hit various ActivityPub + caching issues (e.g. using CloudFlare CDN). With More Mastodon usage there might be some more satisfying solutions than “disable most caching”.
I’ve definite learned more about WordPress Plugin internals by looking at the ActivityPub plugin’s repo. I’m sure I could pick up some stuff for the 100 Days to Offload plugin in the future.
During debugging I was also looking at my web server logs which I haven’t done for years, but I know would be a “proper” sysadmin thing to do. There were a lot of interesting queries that I want to follow up on (bots, sites, tools scaraping the blog and interacting with various bits). It’s the Internet, after all, so let’s look at the connections made!