I have signed up to support it for two main reasons: it’s a Taiwanese project (Skytraq, the company behind Navspark is in in Hsinchu city in Taiwan), and I haven’t seen anything about Beidou before.
They barely made the campaign, but it’s not for the lack of quality. There were a lot of updates during and afterwards as well as the project was developing. Those were good behind the scenes information, got to see what parts of hardware development are more troublesome than others.
The Navspark board
Navspark unboxing: board, antenna, pins
The rewards just shipped this week, and since for this campaign I’m a “local”, I got it pretty early. I got my Navspark GPS/Beidou (BD) version in a big envelope, together with an antenna, some pin and a jumper.
I’ve just recently travelled from Taiwan to Japan on a short trip to check out the cherry blossoms of Kyoto. While it was fun, I did realize that there are a lot of technological details I’m keeping track of, that take up significant mental bandwidth. Technology is helpful even if it takes effort to keep it running. This is a writeup of a non-exhaustive, arbitrarily ordered list of tech I used on the trip, and the way I used them.
Internet connectivity
One of the first concern is how do I get online on the go? There seem to be a bunch of companies providing mobile hotspot rental. The one I wanted to use originally is in Taiwan, and tried to arrange it too late (needs ~5 days in advance). Instead I found another company online called Japan Wireless. They can send a wireless hotspot or pre-paid 3G card to a hotel, or to an airport to be picked up. Since the hotspot I wanted to get was out of stock for the first half of the trip, I went with a 3G card and wanted to use an old Android phone to act like the hotspot.
3G SIM card pack
Picking up the card at Kansai Airport was very straightforward. My Android phone worked much less. Might be getting “too old”, sometimes it couldn’t start the wireless sharing at all, though when it worked it was good for a while. It is also worth enabling “network traffic monitoring” and appropriate warning levels. The pre-paid card had 1G traffic included. Definitely does not recommend running a Play Store update while connected, apps can easily take up 30-50Mb, and 50% of your traffic allowance is gone before you can say “Ice Cream Sandwich”…
Ever since someone donated an IP phone to the Taipei Hackerspace, I’m trying to find time to set up an internal phone network between the hackerspace members. It should be fun to make our own infrastructure. Recently did some research, and started with it. Since if I get into something then I dive deep for a while, this was an intense week. This post is to summarize where I have got in this time
Asterisk & FreePBX
A bit of searching turned up Asterisk, a PBX (“private branch exchange” aka telephone network) software. It looked interesting because it came with a story: a guy building something awesome because he doesn’t know that it was supposed to be difficult. It’s also open source from the start, with a successful company build on top of the project.
Also found, that there’s a graphical control panel called FreePBX that makes using the all-command-line-and-config-files Asterisk easier to use. Both projects had a seemingly very detailed wiki, long track record, and strong following that made it worth checking them out.
The Server
Judging from the original install instructions on the FreePBX wiki, it looked like installing Asterisk & FreePBX is a complex (or rather many-step) process. Didn’t want to litter my own computer with broken installation artefacts, so enter VirtualBox. Using a virtual machine makes it easy to wipe and restart.
There’s a dedicated, preinstalled FreePBX distro based on CentOS, but had enough of CentOS for a while. Instead I just took Ubuntu 12.04.3 as a base, and FreePBX 2.11 and Asterisk 11 from the wiki. The install instructions were clear enough, though occasionally there were small differences needing a fix. Nothing major, but had to play around. After 5-6 reinstalls with increasing experience I got the basic functionality working, calls placed between and such, but the performance and sound quality wasn’t really that good. After thinking what could I improve, decided to take the next step: get out of the virtual machine, and up the version numbers (I’m Arch Linux user with a reason, living on the bleeding edge).
Enter DigitalOcean, a hosting provider that I used for other projects before (cheap, fast with SSD, good service). Set up a machine (aka “droplet”) in their Singaporean center (since that’s probably the closest one to Taiwan). I chose the 1Gb memory instance, because from experience with VirtualBox Asterisk+FreePBX maxed out at around that with a few test accounts.
Upping the version numbers I went with FreePBX 12.0 (from git) and Asterisk 12.1.1 (from download), both are testing versions. Asterisk had an extra dependency of libjansson-dev compared to version 11, didn’t check if any of the earlier dependencies are not required anymore.
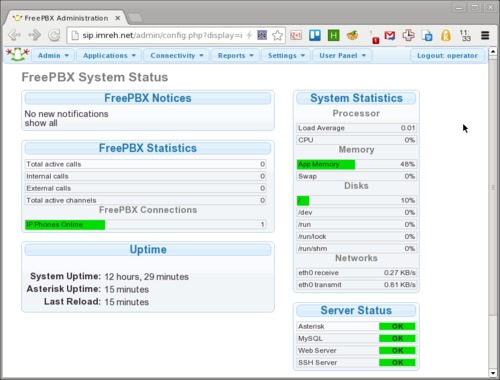
FreePBX interface for Asterisk
Got the whole system working (after a few droplet wipes), and played with the installation with a bit more confidence. From initial experience, Asterisk is a bit like the Linux Kernel. It’s modular, complex, focus on reliability, and the “make menuselect” is a familiar environment after years of “make menuconfig” compiling my own kernel. On the other hand, FreePBX is a bit like WordPress. It has its own auto-updater (just like updating plugins in WordPress), loads and loads of menus, focuses on configuration and tries not to let any faulty module take down the system (found quite a few buggy behaviour, so that’s a good idea). The Kernel and WordPress are two familiar environments, so felt home here too somehow.
Asterisk has a bunch of vocabulary that I’m so far barely familiar with, and lots of functionality that I haven’t had a chance to test yet. FreePBX has a lot of functionality too, and still it’s a bit difficult for me to tell where does an Asterisk function (module, resource?) end and one FreePBX function (plugin?) start. The fact is that I got to feel excited about programmable phone routing (with Lua), fax-to-pdf, hotel style wake-up calls, voicemail recording, call tracing, speaking time, simple conference talks, intercom functionality, regardless from whether it’s a module or a plugin…
Some additional server notes: voicemail requires email out for notification, I set that up with Mandrill and postfix. For such testing it might not be important, but good to secure the server at least a bit with fail2ban and ufw (Uncomplicated Firewall), and probably other things I don’t do well yet. Just sayin’.
Accounts / Extensions
Accounts on the server are the extensions on which someone (or something), a numerical value. The vocabulary and concepts are also new to me, so it took a while to understand how things supposed to interoperate. Asterisk has a bunch of different kinds of extensions, of which I have tried two main ones: SIP and IAX.
SIP
SIP stands for Session Initiation Protocol. As far as I see it is basically a messaging protocol, to set up a connection between two parties, and also provide some other services, for example presence information (Online, Away, Busy….), messaging, and what not. The actual data of the call (voice or video) is trhough RTP (Real-time Transport Protocol).
The voice data in the transmission is compressed with one of the many codecs available:
ulaw and alaw (G.711) are a pair of the standard codecs, okay quality, one of the basic one to have in any client
speex is a variable bitrate codec, haven’t used that much
gsm is lower bitrate, but lower quality too (think of crappy cell phone reception voice)
G.722 is a hi-def (HD) voice codec, really good! I think beats Skype, and on par with a good Google Hangout quality,
G.729 is a non-free codec, shows up here and there, but haven’t had a chance to try it, this is the other HD codec that I’ve seen recommended
In testing, this was some of the learning curve, how to set up clients, and also the server that they can communicate with each other. Who choses the codec (caller, callee, server)? How to prioritize the codecs in different clients? What does it look like (or sounds like) when there’s a problem in this area? How to debug and fix?
Asterisk 12 has two different SIP channels or components: their classic library (chan_sip), and a rewritten one (chan_pjsip). The latter one is a standalone library that can be used for other purposes as well. SIP usually works on UDP, while PJSIP can do UDP/TCP/WebSockets too, and feels stable and fast. Definitely would use that if I have to choose between these two. Still, it is in test phase (both in Asterisk and FreePBX), so not without headaches.
There are bunch of different clients that I tried:
On Linux:
Ekiga is nice, simple, can sign into multiple accounts in multiple networks. Presence information, well integrated into the desktop with notifications and such. Does not seem to be able to handle non-standard SIP ports (which will be an issue further down)
Linphone is really multiplatform (Linux, Win, OSX, smartphones…), but it was crashing on me quite a bit, doesn’t integrate into the desktop (no notification just sound on call), and can be confusing with the lot of settings (the control panel looks a mess). Can handle non-standard ports too.
SFLPhone is good, works pretty well, simple, and can do IAX communication besides SIP.
On Android:
Android actually has full SIP handling capabilities built in for a while now (under “internet phone”). That would be awesome, if there were more information how to set up and use, but in theory a SIP account can be fully integrated into the system.
CSIPSimple really impressed me, probably the best working client I found. Integrates with the system (calls are handled as ‘calls’ with all the icons, history, and so on), good sound quality (can use the G.722 codec) and so on.
SipDroid, VIMPhone, LinPhone…. these other clients, don’t even remember them, all of them fell short somehow
Zoiper stands out as well, not just because it’s multiplatform, but because it’s pretty much the only one I found that can do both SIP and IAX. The Android system integration is not as close as CSIPSimple, but quite okay.
One of (the many) good thing about SIP that it is well known and pretty well supported. If there’s a “softphone” (phone in software), it’s quite likely to have SIP communication capabilities.
The bad thing about SIP though that it is well known and pretty well resented by the phone service providers. Many of those providers block SIP messages on their network, or sabotage the connection in some other way. On my own cell phone / 3G provider’s network, I couldn’t connect to Asterisk. In the forums some suggested that changing the port number that Asterisk listens on for SIP connections can solve things – and indeed after moving away from 5060/5061 to somewhere else, I could connect. The celebration was short lived, though because even though the calls now can reach the destination, RTP communication (the part that actually transports voice) was still broken. I don’t want to use VPN all the time (though might need to soon), and want to keep moving parts and settings to the minimum if I want others in the Hackerspace to join this network as well, thus SIP looks like a no-go because of the phone companies (darn).
IAX
Looking around, I found another type of channel, using the IAX (Inter-Asterisk eXchange) protocol. The bad thing about it that it is much less supported, but in turn it is not blocked by the phone companies either (since they don’t know about it).
Using SFLPhone and Zoiper I could successfully talk over 3G! Still it is not all good, the devil is in the details.
Zoiper incoming call on Android
It’s good that no need for custom ports
It’s bad that the IAX channel seems to be more unstable on Asterisk (or maybe I messed up my install after a while?): some extensions have trouble logging on for a while until the server is restarted; the wakeup-calls plugin misbehaved with IAX extension.
The less support also means less choice in clients. The ones I found cannot do G.722 so no HD voice anymore
Has a security setting (requirecalltoken) that not all clients support, not sure if there are any implications.
It’s also good, that Asterisk can route incoming SIP calls onto IAX extensions (i.e. the caller doesn’t have to care what technology the callee is using). On the note of routing, I could set things up such that outside calls can be routed into the system. E.g. every hackerspace could have their own Asterisk server and interoperate to call members at other spaces – sounds like a lot of work and might not worth it, but it also sounds awesome.
Summary & Future
I had a lot of fun playing with Asterisk. On the surface phone networks are familiar to everyone, but going deeper both makes things more confusing and opens my eyes how many possibilities there are for making something useful.
There are a lot of things that I thought about, but haven’t tried yet:
Programmable dialplans (“what happens when a call is received”), via Lua. Lua is an awesome language and probably a lot more large piece of software has it embedded (since that’s one of its strength)
There are a bunch of other protocols and acronyms in Asterisk, for example Secure Real-Time Protocol (SRTP) and ZRTP, that could worth figuring out for a deeper understanding and security
There’s an Asterisk on Raspberry Pi project that looks interesting (if nothing else then how do they lower the memory usage below the RPi’s <512MB?). Since Asterisk can be used with multiple servers in a network, the RPi can provide one kind of service (e.g. GSM gateway) while other servers with more resources do other stuff
Using physical phones in the network, for example traditional phone network to come into the server, and IP Phone to ring out. Maybe setting up fax endpoint (and sending it out as PDF or printing it). Basically anything that is working on the threshold between physical and digital.
Should check out how the likes of Line, Voxer, and Viber are doing VoIP on Android, do they have any interoperability?
How about Twillio, can their system be a similar PBX on a much larger scale?
The funny thing is that looks like the original IP phone that started this whole adventure does not work with Asterisk. Never mind, it will be good for another project.
It looks like Bitcoin is developing really fast these days, both on the usage and on the technical side. There are a lot of usability issues, and ideas for bitcoin services that look great on paper but don’t exist yet. Many of those ideas will be created with time, some of them though it’s better to go ahead and make as soon as possible, to let people use and see the advantages and disadvantages.
One of the most interesting ideas I’ve read so far is the creation of the Hierarchical Deterministic Wallet, or Bitcoin Improvement Proposal (BIP) 32. It is trying to solve the problem that currently the standard Bitcoin clients need generate independent new Bitcoin addresses to the user, and store a piece of secret in a wallet file for every Bitcoin address a person has. If that file is gone and not backed up, the person will lose access to those coins permanently.
Others tried to fix this too, like Armory and Electrum, two clients that can generate a whole chain of addresses, though have their own limitations that I don’t go into (though at the moment I’m using Electrum for most my coins).
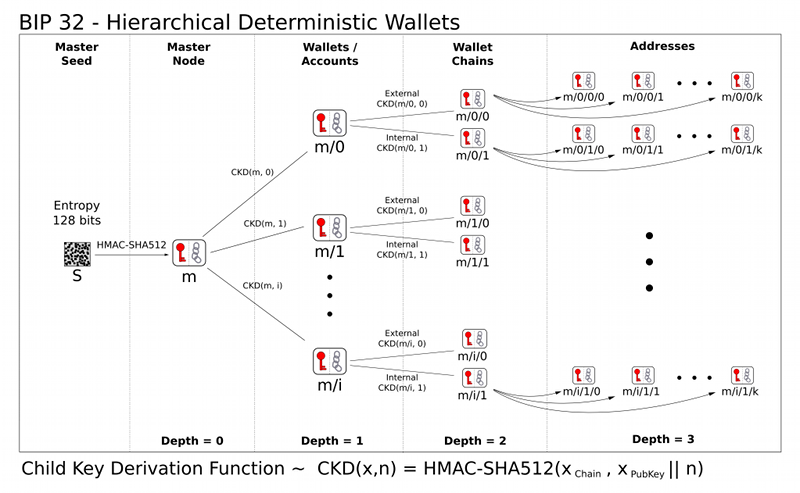
BIP32 on the other hand can generate infinite number of new address from a master secret, and all of that arranged in a hierarchy that one can create well separated accounts and addresses very easily. One example is creating a separate wallet for each of the branches of a store, or for different websites a person is working on.
BIP32 key derivation scheme (click for full size)
One practical problem with BIP32 was that I couldn’t find any wallet management software for it. Electrum has that in the works (I think for the 2.0 version) but they are not there yet. Had to make one myself to try it out.
Design choices
I wanted to make something easy to use (as much as possible given the hairy details), secure, and powerful enough.
For ease of use, it’s a single web page that does all the work with Javascript and HTML; try to have as few moving pieces as possible; make sensible default choices, e.g. for the structure of the hierarchy.
For security the keys entered in the page are never transmitted over the network; the created transactions can be checked independently by a 3rd party (can decode it with Blockchain.info); the single page can be saved
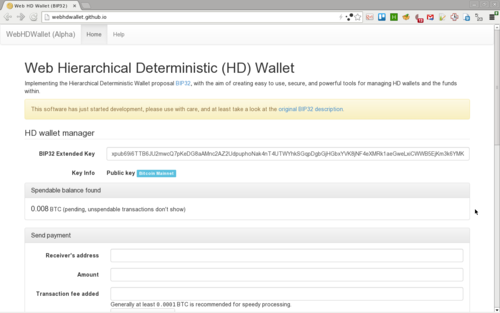
For power it can use both public keys for querying balance, and private keys for actually preparing transactions; it generates addresses automatically; it has everything needed for transactions within one page, with very little external dependency; have access to advanced functions if needed.
WebHDWallet main screen
Implementation
It took a few day, it it was too bad to get to a working prototype: it is hosted on http://webhdwallet.github.io/, but can be downloaded with all the code to makei it a stand-alone application.
I didn’t want to implement the BIP32 extended public/private keys generation because someone better than me already did it at BIP32.org, and it is also a good way to separate responsibilities. Two independent crooked website is much less likely than one, isn’t it?
The Bitcoin functions, including using the BIP32 keys, are delegated to the bitcoinjs library. Apparently there are a bunch of forks of the original one at various stage of advancement, and incompatible added features. I have chosen the fork one that looked the most active, by BitGo, to import into this project. So far so good, maybe will do some porting of features between the forks later.
The “standard” way of creating addresses from here is creating two chains: an external that the user is supposed to share with whoever wants to pay him or her, and an internal chain for change addresses (to eliminate address reuse as payments are sent). The site creates the bunch of these addresses starting from the 0th one (as computer programming so often start to count from 0).
All of these addresses are checked with the Blockchain.info JSON API whether they ever had any transactions. If they did, then check for the spendable coins, and generate some more addresses in the chain. This tries to reduce address reuse and ensure that all addresses used so far are checked. Of course, this is one of the weaknesses of BIP32 – one can never really be sure without a lot of computation or out-of-band communication whether all the addresses ever used with the key are accounted for.
If any spendable coins are found, then the user can create a new transaction. I didn’t put in too much effort into finding a good coin-selection algorithm, just start from the oldest one and add more to the input side of the transaction until there are enough to cover the desired outgoing amount. Apparently, though, that is a good way to do it, so fair enough.
If the extended public key is used, then the page only knows enough to create an unsigned transaction. This can be checked, and hopefully later I’ll be able to implement the feature of signing such transactions (with the same page) when being offline for security. If the private key is present, then a proper signed, spendable transaction is made, and ready to be submitted via the Blockchain.info Broadcast Transaction tool.
The receiving addresses have QR generation too. The chain addresses not, because they shouldn’t be used directly – this is just some opinionated programming.
Usage
The incoming BIP32 keys are generated as it is described in the help section of my page: choose a hard enough passphrase, and generate a child key as custom m/i’ child path (this should really be standard, by the way). It just means take the master key (m), and create the ith child in “private derivation” mode (hence the prime). Can see the original BIP32 page for some of the details.
This leaves you with an extended public key (something starting with xpub…) and an extended private key (xpriv…). Should keep the passphrase from the previous step as well, but definitely these two keys.
When one of these keys is plugged into the page, it starts to generate the appropriate keys for the two wallets, and the balance shows up. When any balance is found, a new transaction can be created, and sent off to the network with Blockchain.info.
To prove that I made this work before at least, the extended public key to generate the listed donation address of 17NWCFWo8EvFp7vtkbRH6ec3DEdxZhrhrd is xpub69i6TTB6JU2mwcQ7pKeDG8aAMnc2AZ2UdpuphoNak4nT4UTWYhkSGqpDgbGjHGbxYVK8jNF4eXMRk1aeGweLxiCWWB5EjKm3k6YMKoWN5VT (receiving address chain index 1) – go ahead, try it. Also used the page to create a small transaction – sending the from receiving address chain index 0, which also used the change chain index 0 address. When that worked, that was a relief. :)
Future
There’s a lot to do about this project and related services to make it more usable and interesting, the Issue Tracker is bursting with ideas. Here are some with higher priorities:
really make it offline usable (which would remove a lot of security concern, probably). Will need to think much more about the internal implementation then, how’s the most user friendly to create new transaction if you cannot go online to get data (what and how to import between online and offline)
make a usage video
generate addresses in the receive/change chain at arbitrary indexes (could be useful)
add QR code reading to the input field, probably via jsqrcode.
implement storage of retrieved data so it’s more user friendly when on non-public computer
talk to the bitcoin network directly, either to get the input or to send the transaction. Some groundwork is laid down in a blogpost recently about using the raw Bitcoin protocol in Python.
implement my own server/API for Bitcoin/Litecoin/Dogecoin that can be used with BIP32 wallets, and probably Blockchain.info compatible. Currently there are no good service for such altcoins (even if it would be pretty straightforward I think), and for the Testnet (so not risking real value to try things out)
implement a Point-of-Sale app (I guess on Android), that uses an extended public key to generate receive addresses for incoming transactions (totally hold-up-safe, and crooked-employee-safe payment method)
implement a WordPress plugin that uses extended public key to generate per-post donation addresses (for the donations themselves, as well as analytics-via-payment)
Well, at least the first step is done. All source up on Github. Would love to hear from anyone who used it, and what do you think could be improved upon.
Since my last exploration of bitcoin, there are a lot of things happening in that topic, and the geekiness of it (among other things) didn’t let me go. There were a lot of talks about one more more Bitcoin ATMs (like Lamassu) coming here to Taiwan, but all of them are months in the future. I thought maybe it could be interesting to build my own – let’s call it – vending machine, for fiat-to-bitcoin transactions.
There were other people making similar effort, for example the Open Bitcoin ATM, but I felt they fall a bit short and unlikely that I can get the same parts over here.
Preparation
For a vending machine like this to work, there’s really only one piece of equipment is needed, the bill acceptor. I have looked around on eBay, and Alibaba for a Taiwan Dollar (TWD) bill acceptor, but there’s little to none to be found. Looks like I still got lucky that one of the big vending machine manufacturers, International Currency Technologies (ICT) is actually local (less than 1 hour on public transport from here, maybe?).
Looking around their side, they have plenty of bill acceptors (many but not all can do TWD). They don’t have any local distributor, so I got in touch with their sales directly. The first guy didn’t speak any English, but somehow after a handful of emails I got to guy with pretty good English (which is unfortunately not as common as I’d like it to be). A few weeks (yes, weeks) of emailing, and some nudging phone calls I got some useful information out of them.
I asked, what do I need if I want to use a bill acceptor for “a digital goods vending machine”, and maybe a thermal printer (that’s cool, wanted to use one for a long time)? They had some advice which parts do I need, and how much would they cost. Their recommendation:
GP-58IV thermal printer (an advanced, not yet announced version of GP-58III) [US$150]
a payment system board to make it easier to use them together and with an external control board (no mention of it on the website) [US$140]
It does add up quite a bit before any housing, brains, and display – definitely more than the Open Bitcoin ATM’s supposed $165 tag. But it looked like it does worth it, I went ahead and ordered it (+5% VAT, since I’m not a company).
Vending machine parts: bill acceptor, control board, thermal printer.
The parts arrived quite quickly (as a reference, 3 days ago), within less than a week of the order, because they were in stock. Unpacking is fun, though soon it was obvious that not everything is smoothly on track.
The guides attached were barely scratching the surface, contained no information on how to make the units work with the computer (i.e. no protocol, no nothing), maximum referring to some software that I didn’t have access to, and would run on Windows anyways as opposed to my Linux system.
Asking and re-asking a bunch of questions to the sales guy made it clear:
the thermal printer does not need the payment system board, and indeed it cannot even talk to the printer (though an attached documentation says the opposite). Need a “main” board to print to it.
the thermal printer on the order was 12V supply and RS232 connection, while mine is 9V and USB, and apparently the former does not even exist. It uses wallplug instead of shared power like the bill acceptor and the payment system board.
the payment system board cannot control the bill acceptor with the current RS232 cable, because its single RS232 connector is for the external “main” board that I should make. If I plug in the bill acceptor in there, the payment system has to be stand-alone
the bill acceptor comes with a power plug which is type 172340-1, that none of the local computer part stores know, so I cannot (easily) supply power to it. They will send me another adaptor cable to improve on this.
Based on all this it seems like that even if they knew my use-case correctly, the actual parts I got do not fit together the way they represented it, and there’s plenty of confusion about the specs. I really didn’t need the payment system board, for example…
All in all, my contact was quite helpful, and pretty quick to reply, though it is still quite painful first encounter with system integration, and there’s a lot more to fix with the hardware, though was good enough to start.
Assembly
There was a lot more querying in the emails about related documentation. Got the description of the ICT-104 protocol to communicate with the bill acceptor (it’s not too bad). Got the windows printer driver for the thermal printer, though managed to use it without that (and installing Windows): it turns out that the printer implements the Epson ESC/POS protocol, for which there’s already a python library, the python-escpos. It seems to be pretty dead, but good enough for initial testing.
Thermal printer test print
The test prints are “okay”: the text is fine (32 char/line), barcode and qr code should be usable but there seems to be some communication problem that breaks images (like the space shuttle on the above picture), that needs to be debugged (seems like not all gifs are created equal, for example, some are more reliable). Oh, I used Dallas Clayton’s poem, “Good/Bad” for the testing.
Played with the bill acceptor as well, using some pins and a bench power supply (set to 12V, the bill acceptor eats max ~0.6V when the motor is running), and hoped that I don’t blow the circuit… So far so good.
The vending machine flow is something like this:
turn on
read receive address of customer
accept payment
calculate outgoing bitcoin
send payment
print receipt
I was doing the printer testing in Python, and RS232 is pretty easy in Python, so just cobbled together a command line vending machine interface in Python.
Turn on, communicate with the bill acceptor, display some initial information that I know that it’s going well.
Start running zbar in the background to read qr codes from the computer’s webcam. Using the console to exchange information, didn’t have time to fix up the python-zbar integration, though it should work as the Electrum bitcoin client uses it as well.
After an address is read, read the notes of the bill acceptor, and update the sum of received pay. This is listening on the RS232 line for specific codes, and replying to tell the bill acceptor what to do (i.e. accept/reject).
When the user is finished and signaled that to the interface, calculate the outgoing value, send the payment through a payment server. The payment server is a nodejs script that accepts payment information through a REST API. It does it very badly, insecurely, using the wrong REST model (it should be “POST” to do anything with consequence, never “GET”), but it does work. It connects to a local bitcoind instance (over SSL at least, not that it matters in this case, but at least I know SSL will work for the “real” server), which at the moment is connected to the testnet, not the real one.
After the payment is sent, print the receipt with some useful information on it, and a bitcoin logo for good measure.
The current stages of the both the bitcoin vending interface, and the payment server are open source and online. And it worked, here’s a video of it in operation.
Future
I hoped it would be in better stage before tomorrow’s Bitcoin with a Lawyer’s Eyes event in the Taipei Hackerspace, but either way it is good to think ahead further.
If I want to make it really useful, and a “real” machine (one that you can kick or pour beer over it and still keeps working, as one of my friends put it), there are some specific things I can improve:
enclose it in a box: metal, laser cut acrylic, …?
better bill acceptor: keep bills in escrow before the payment gets through, disable acceptance unless we are at that stage of the workflow, set maximum vending amount in one go.
designa a better interface, that can do multiple payments before needing to restart
price not hardcoded into the software but dynamically set
print relevant links embedded in qr code, eg. transaction on blockchain.info
make the payment server secure and improve the overall security, eg. have a code or activation for starting up
hook it up to the proper bitcoin network (this is the scariest part)
build a few more, fund them, and put somewhere accessible
Now back to work.
Ps: My purpose of building any such machine is to make it easier to acquire bitcoins, this spreading their usage and increasing their usefulness. If you feel like tipping, my address is 1GxSUTrw5onv9HbJhKN5PVhuyxm4j75X8d. Thanks!