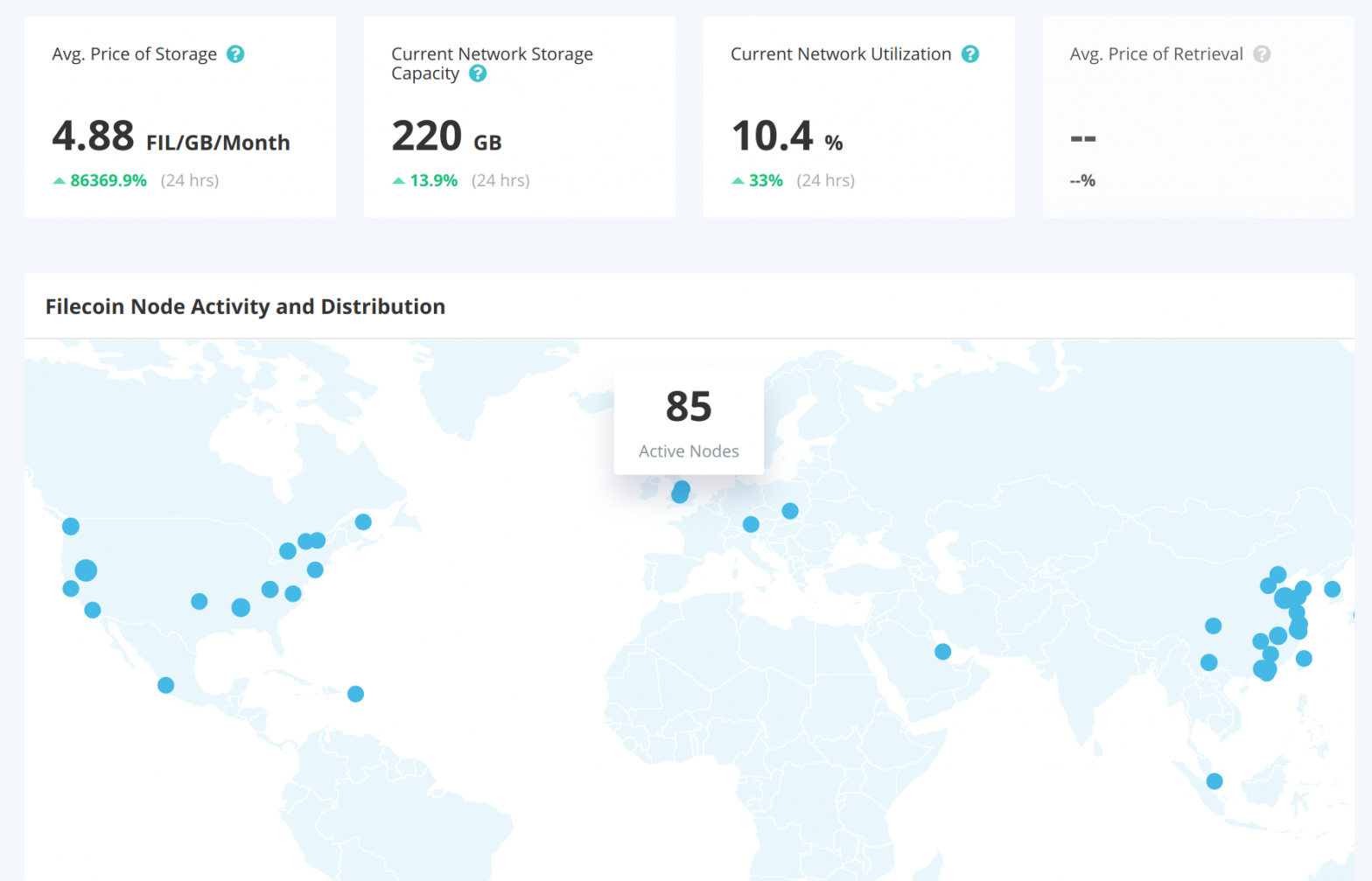
I’m an interested user of many novel technologies, some examples being cryptocurrencies and IPFS. One technology that I was keeping an eye on was at the intersection of that two: Filecoin (it’s using blockchain and built on IPFS by the people who made IPFS). It aims to be a decentralized storage network, where nodes are rewarded by storing users’ data, in a programmatic and secure way. After a long wait, the Filecoin repositories just opened up a few days ago (see also the relevant Hacker News discussion). This allowed everyone to give the newly deployed development chain (
These are very early stages for the technology, so take all my comments with that nurturing point of view. I’m glad they release stuff at their version 0.0.2 as it happened, even if a lot of things are in flux. Also, I’ve spent a bunch of time with IPFS, a lot of parts of the experience with Filecoin (or rather with the initial implementation of go-
Getting started
The first thing is obviously getting and installing the binaries for the project. The initial implementation is go-
On my ArchLinux machine, these (or newer) versions are already a default, so it was easy to get them, while on another Ubuntu 18.04 LTS that I used, you’ll have to do some manual installs if you’d like new enough versions. Still, it’s doable.
To facilitate installation on my system, I’ve also made an ArchLinux package for go-
One surprising aspect for a new user is that the initial compilation can take hours. Emphasis added, it makes a lot of things a lot more difficult. The source of this long time to compile is the parameter calculation in the rust libraries for the secret sauce, and
One note on the
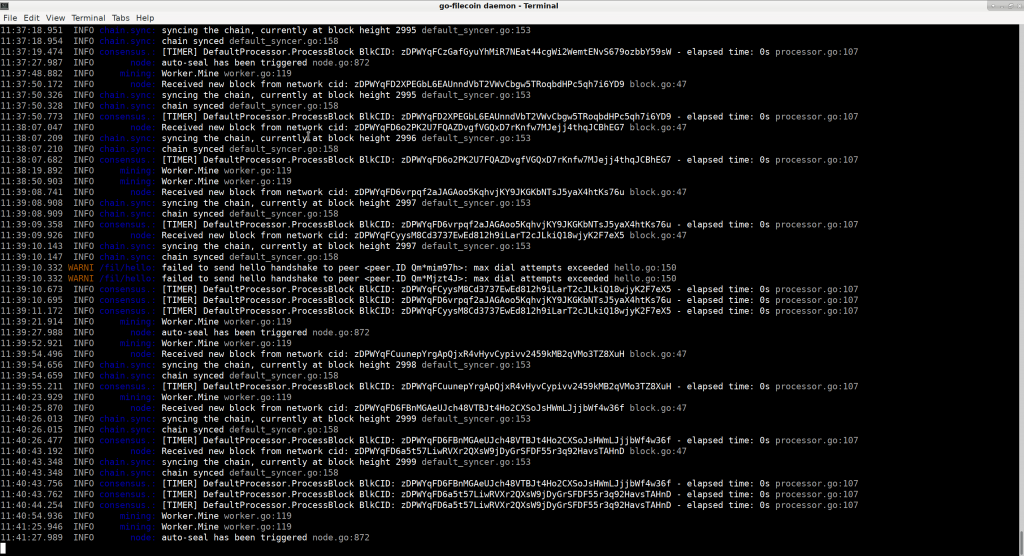
In the end, however, I had my binaries running, and could turn to their Getting Started Guide, and starting to sync some Filecoin blocks (both on ArchLinux and Ubuntu). Feels good. :)
Concepts
The next step was giving a spin to the rest of the getting started, such as storing some
One of the first conceptual difficulty is that managing
- as a
miner I set up a node with spare storage space, and I see the coins coming in - as a person who has files to store, I just say “store these files”, and be done with it if I have “enough” funds
How it really works:
- as a miner, unless I put in a price for my storage, nothing will happen. That price is valid for a certain amount of time (a number of blocks), and I can put in another price alongside, but don’t seem to be able to revoke a price. Yeah, I can see how this could be done automatically in the future, but still have some awkward aspects, more on this later
- as a storage user, I have to specifically choose a miner to store my data. This is one feels a lot more difficult to handle, as it has proven a pain to find where can I store stuff, and have to manage the lifecycle of that storage (e.g. have to store the message ID where the miner agreed to the deal, otherwise I don’t seem to be able to look up later, and thus don’t seem to be able to check the feedback whether the miner is done storing the stuff they said they will)
This (current) manual management really puts the network to the
Another part of the concept that is difficult at first, that there
When setting up a miner, one also has to provide a “collateral” for the storage. I would guess that would be the price one loses if the storage goes unavailable during a “contract”? But it’s not totally clear yet (will have to dig more into the docs). What’s difficult from this is that how would one in normal circumstances have enough coins to bootstrap (provide collateral and be able to start to mine)? On the
Also might be somewhat of a surprise, that it seems nodes get rewards on mining based on not the storage they have, but the amount of data they stored on behalf of clients. Combine this with the manual seeking out of miners by clients, and it currently all relies luck, whether or not someone’s miner was found and was utilized. Otherwise it will be just treading water. I guess this will be better with an automatic market as well, in the meantime might just set up 2 nodes that pat each other in the back store files on each other to see the effect first hand.
Usability
The usability issues I’ve run into (that are the majority of the issues, I think) are not surprising given how early stage everything is, but
Given that the whole Filecoin chain is less than 3 days old now, it already takes hours to download the whole chain starting from scratch (depends on the network, but still getting about 30-60x the download speed compared to block generation speed, which is very small multiplier). I think this will get old very quickly.
When I stopped my machine overnight, and started up the next day, it also took quite a long time till it started downloading blocks again. Seems like the daemon works the best when it is kept on for a long time and can build up a lot of p2p connections, but that’s just a hunch.
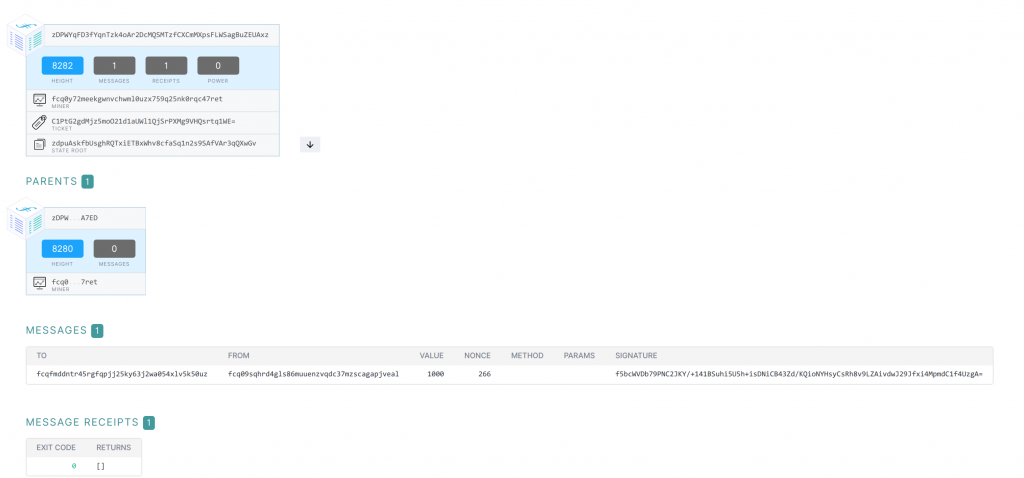
Then when storing and retrieving data, it’s a bit inconvenient how much information the I have to keep track of: the miner’s acceptance message to be able to check the storage status; then the miner’s address and the piece of data’s content ID itself so I know exactly from where to retrieve it back (“where have I put my data?”). I guess this is again automated for later, but strange that it doesn’t seem to be stored somewhere (maybe I’ve missed it).
The retrieval times can be quite long as well. I generally get 3-6 minutes retrieval times, which is 6-12 blocks worth of time – and given that one pays buy the number of blocks the data is stored for…
As described above, the miners have to set their price for a given time, and storage clients “contract” them for a specific piece of content for a number of blocks. It feels like that as a miner one wants to set short times so can adjust the price as needed. On the other hand, storage clients can then only contract for short time, and need to continuously “recontract” the data. First I thought this might be super annoying, as then probably would spend a lot of time uploading data, but I think the underlying storage is IPFS, so the “recontracting” might actually be really cheap (as the network already stores more copies of the file at that time).
Looks like the current “block” size of the storage is 256MB, meaning that files stored take up multiples of 256MB as stored. If I contract 2 small files to a miner, it would still use up 2x256MB at least. Some experiments I’ve done certainly seem to show that, but not sure about that mechanism. Also, the “nightly” network seems to be using much smaller blocks, but not sure it’s because it’s the future, or because the nightly network requires that for development?
Given these relative complexity of storing files and the block size effects above, it seems like Filecoin so far is aiming at medium / large files, not small ones, so for example storing a source code repo might not be nice currently. On the other hand, this feels temporary, the contents the nodes store seem to be same kinds of content IDs as IPFS uses (not surprisingly), and IPFS can slurp up directories, to be referred by a single content ID (and all files in there referenced within). I would not be surprised that sooner rather than later, one would be able use a similar import for batches of files.
The data stored on the network is also just the content, and none of the metadata. Thus I need to keep track of extra info (“this Content ID is an MP3 with this title, &c”). This will likely require extra layer of tooling on top, though the current behaviour is just what comes from IPFS, I believe, which has some file type guessing in the interfaces – but also at least have filenames if directories are stored, as mentioned above.
I also has to import files into the local Filecoin client, before it can be contracted out. Thus the amount of space available on my computer determines quite a bit how much data can be stored on the network as well: everything is using at least 2x its own space (once in the filesystem, and once imported in the Filecoin node).
Lot of the other usability issues also come from the command line interface (CLI) of go-filecoin, which is not yet very polished (again, not a surprise). For example most commands output formatted text, and have to add the “–enc=json” setting to have a JSON output. Except a few commands output JSON by default… Then the formatted text and the JSON output is not exactly the same fields, the two have different entries…
For many practical tasks, one also has to chain a bunch of the commands to get from A to B, and thus I think users of go-filecoin currently will have to be pretty good shell scripters (similarly to the go-ipfs users…). As an example, to check whether a miner is reachable (so whether I should even try to contract it for storage:
# Use this to get all the miner storage price offer
go-filecoin client list-asks --enc=json
# Pick a MINER that you like above
PEER=$(go-filecoin address lookup $MINER)
# Check if the peer has a path to it from us, and try to ping
go-filecoin swarm findpeer $PEER && go-filecoin ping -n 1 $PEER && echo "Contacted!"Or scaling this up, finding all viable miners that one could connect to (though would still need price info in a practical setting):
#!/bin/bash
function checkminer() {
local MINER=$1
local ADDR=$(go-filecoin address lookup $MINER)
go-filecoin swarm findpeer $ADDR &> /dev/null && \
go-filecoin ping -n 1 $ADDR &> /dev/null && \
echo "Possible viable peer: $MINER $ADDR"
}
export -f checkminer
go-filecoin client list-asks --enc=json | jq -r .Miner | sort | uniq | xargs -I{} -P 15 bash -c 'checkminer {}'Or just see the (very helpful) examples in the getting started guides linked above. I’m not sure that these above are convincing, but start to use Filecoin, and you’ll find saving information into shell variables, and running scripts in no time…
There are also some unexplained workflows (as far as I can tell currectly), such as whether it’s possible to send coins from one wallet to the other directly? And if it is possible, how? I think the faucet does it, so maybe that’s the code to look at, not sure if it’s anything special to the faucet, or just using the API. There is also the concept of payment channels (“go-filecoin paych”, the commands within), which are set up to handle periodic payments to miners based on their proof of storage (Proof of spacetime? Proof of replication? One of the many proofs I’ve seen mentioned in the docs, sorry if not precise enough). Those are funky, as there might be a lot of coins tied up there with failed storage contracts (as for example I was trying to contract my own node to store something, and that didn’t work, as it didn’t find a path to itself – but still put aside / tied up the coins in a channel :). I wonder how would one release coins from there? Or how to get back the “collateral” from the miners if one wants to decommission one?
Development experience
The go-filecoin repository seems to be pretty well setup, the issue templates work well, the repo seems to be pretty active, there are many ongoing issues and PRs. Seems like a lot of people are filing issues (early adopters tend to) which is great to see, and the developers replying & following up there is very promising. Some of the tooling is a bit behind, though, such as some version number issues, some deployment might be more difficult because of the gx tool used (that should require new code release to IPFS to be able to referred to as each release there is immutable, at least I guess it’s how it works), which makes some cycles longer. I was also checking out the Community section and used the chat on Riot.im/Matrix. That was a hit and miss – had my issues with Riot (which I wouldn’t go into now), but at least there were some good exchanges and quick help (and given some back too), I guess it should be all much busier during the week.
Into the future…
If the concept of Filecoin is interesting to you, would suggest to check it out, dig into the whitepaper (which I need to review again too), go store some data, look around the network stats, watch some Filecoin related talks for background, and file some issues if you run into any problem… I wonder when the “mainnet” release of Filecoin would be, but from the above I hope not too soon. There are plenty of things to fix, while if you dig deep enough, you’ll see that this project is trying to solve some really hairy problems, which is much easier to appreciate after trying out this team’s proposed solutions to them. The future of distributed storage is interesting, regardless of how big extent Filecoin solves things.