I’m a technical and scientific person. I’ve done some online courses on machine learning, read enough articles about different machine learning projects, I go through the discussions of those projects on Hacker News, and kept a bunch of ideas what would be cool for the machines to actually learn. I’m in the right place to actually do some project, right? Right? 🚨 Wrong, the Universe says no…
This is the story of how I’ve tried one particular project that seemed easy enough, but leading me to go back a few (a bunch of) steps, and rethink my whole approach.
I bet almost everyone in tech (and a lot of people beyond) heard of AlphaGo, Deepmind’s program to play the game of Go beyond what humans can do. That has evolved, and the current state of the art is Alpha Zero, which takes the approach of starting from scratch, just the rules of the game, and applying self-play, can master games like Go to an even higher level than the previous programmatic champion after relatively brief training (and beating AlphaGo and it’s successor AlphaGo Zero), but also apply to other games (such as chess and shogi). AlphaZero’s self-learning (and unsupervised learning in general) fascinates me, and I was excited to see that someone published their open source AlphaZero implementation: alpha-zero-general. That project applies a smaller version of AlphaZero to a number of games, such as Othello, Tic-tac-toe, Connect4, Gobang. My plan was to learn by adding some features and training some models for some of the games (learn by doing). That sounds much easier to say than to do, and unravelled pretty quickly (but probably not as quickly as it should have been).
I’ve picked the game Connect4, because a) I used to play that long time ago, b) feels like a relatively simple game, while still interesting, c) the repository didn’t have a pre-trained model for the PyTorch platform, that I wanted to try.

PyTorch was the choice, as it works both on GPUs (as the preferred workhorses of machine learning projects) and also on my laptop that only has a CPU to use.
The unraveling
Getting started was easy enough. The neural network setup seemed to be pretty much the same between the different games, so I’ve just copied and adapted another PyTorch setup to Connect 4. Run it briefly on my laptop, and it was doing things, it was playing games. The training takes place in 3 phases: first generating some example games (from random valid moves, or existing model, I think); next train the model on those example games to recognize better what it takes to win; finally the new model is pitted against the previous one, and either accepted or rejected as the basis for further training, based on the win-draw-lose percentages.
I’ve trained for a
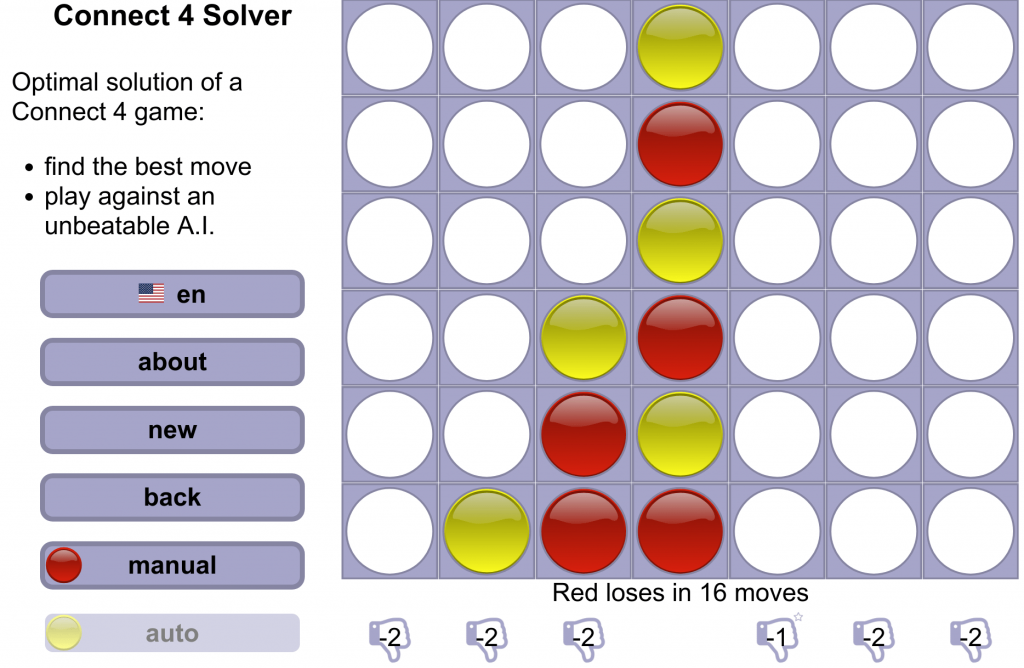
I’ve started to look for some better Connect4-player software that I can pit the trained model against, when realized that it is an already solved game, with a perfect strategy! You can see either Expert Play in Connect-Four by James D. Allen, or this entire masters thesis, A Knowledge-based Approach of Connect-Four by Victor Allis. I … am yet to read either, but since I found an online implementation of the Connect 4 Solver, I knew that will help me to test how well the trained model work. Since the game is solved, and the first player will always win, that should help simplify and the training a bit, right? For example, I would know when the perfect strategy is achieved: when in the post-training it consistently gets 50% wins, 50% loss, and 0% draw, then it plays perfectly.
Trying to validate this hunch, I was training it on my laptop, but the training times went up tremendously as the number example games are increased in each iteration. My laptop generated example games fast enough, but then the training was getting slower and slower. Needed to search for an alternative. Fortunately, I had access to an idle NVIDIA Jetson TX2 machine, which is more-or-less a 64-bit ARM machine with some pretty decent GPU with plenty of CUDA power attached. Was designed for machine learning, and should be perfect (or rather overkill?) for my application.
Setting up wasn’t too difficult, though I think the
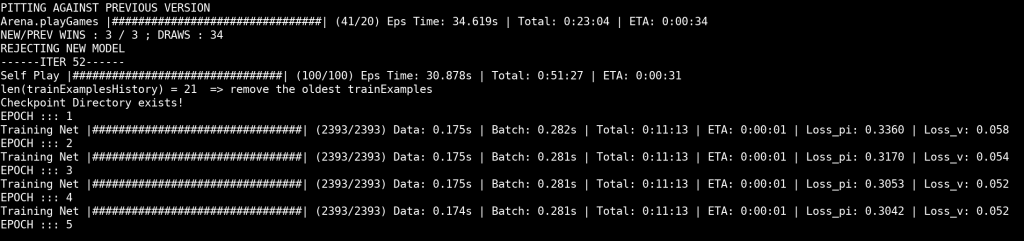
What I ended up seeing is a kinda static phase. Almost all
I was trying to change the code a bit, based on some quite interesting issues opened on the original repo. For example, there’s one asking why the Monte Carlo Tree Search is set up as it is, and whether another setup would help it train faster? (Faster is good, faster to see both successes and failures in the whole training process. Can’t waste time, when everything takes hours!). Then there’s another question regarding the models ending up in draws all the time (that’s familiar?). Or this very straightforward “Connect4 Not
Why the implementation uses its neural network setup as it does, and does it work since it is much simpler than the original AlphaZero, as mentioned in the code author’s blog? What do the different neural network designs mean, and how can I see quickly if I’ve set up one that has the potential to learn correctly or it’s a dummy? How does the AlphaZero algorithm actually work? Is it all tied down properly, or some parameters/implementations are not clearly defined in the papers, as the issues I’ve mentioned above hint? How does PyTorch work and how do I use properly (and optimize it, much further down the line)?
You might say these questions are very basic, fundamental, and that’s indeed the case. One misses the fundamentals in the hubris of jumping into a project that just because I have a general birds-eye view of the problem and some code of an unknown quality that someone’s written. It’s not all set and garden path to some sweet easy wins. I am not writing off that two weeks of experimentations as waste, but do need to change the approach.
Now what?
At this point going back to the basics sounds like the right way, and with more humble, step by step learning build up the skills to make more sense of the whole project.
- Get to know PyTorch, and make some working examples building on the tutorials (or get inspired by them). Looking at some online courses like the one by IBM shared on edX. Work until the tools are getting comfortable.
- Read the AlphaZero papers (the original, and the follow-up linked from their website), as well as explore around the topic following their references and articles referring to them
- Properly review the source code of the open source implementation I was using, and the accompanying tutorial. Not just skim and pull code blindly.
- Bonus, find some higher
level inspiration for neural network design (as getting the network right is the big part of the whole thing, that’s how it look). Sources like The Neural Network Zoo by the Asimov Institute, which shows different networks for different kinds of tasks.
This should get me to a point where the original plan has some chance of succeeding. And if it sounds like a common-sense plan, it is because yeah, maybe that’s what a lot of occasions need, a bit more common sense… I wonder if it’s a radical thought, but it took me a while to get to that. 🤕
In the future should also probably compare the different machine learning platforms as well, TensorFlow, Keras, MXNet, maybe there are other ones as well, and run some sweet-sweet learning in the cloud (have some spare credits here and there, I wonder if they will expire by the time I’m done with my “common sense plan”).
I wonder though if others also run into a wall like me, and if did, what did they do? Is there any other lesson in human learning that this machine learning story can provide?
One reply on “How not to start with machine learning”
Thank you for this write up. I’m studying AL and thought of this as a fun project for the RL class, but I’m thinking it may be too much to handle.