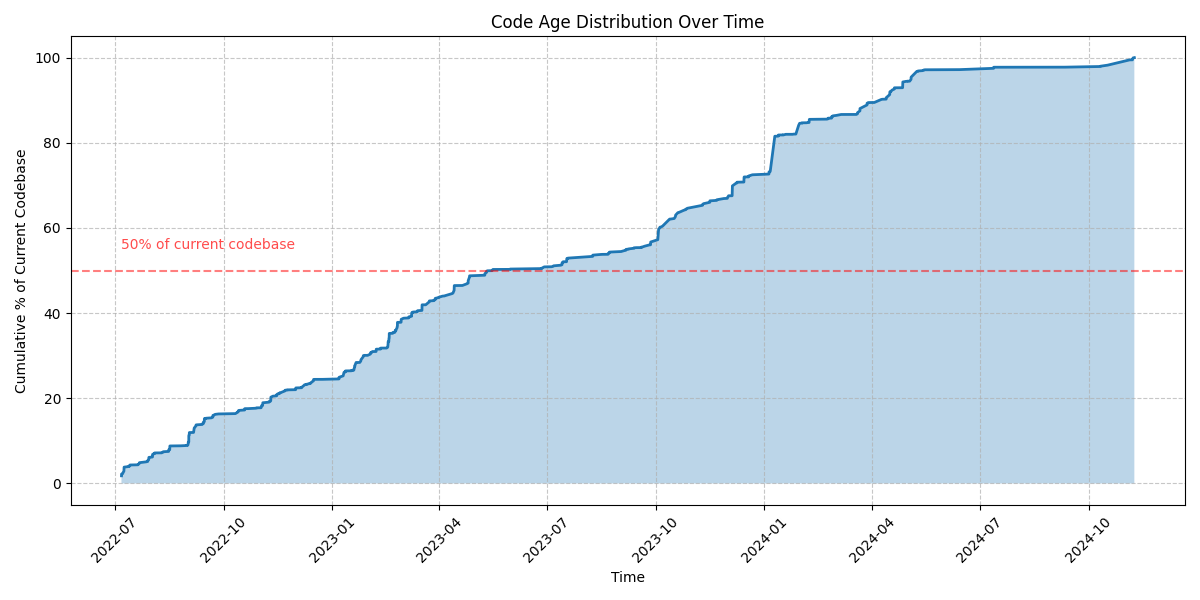
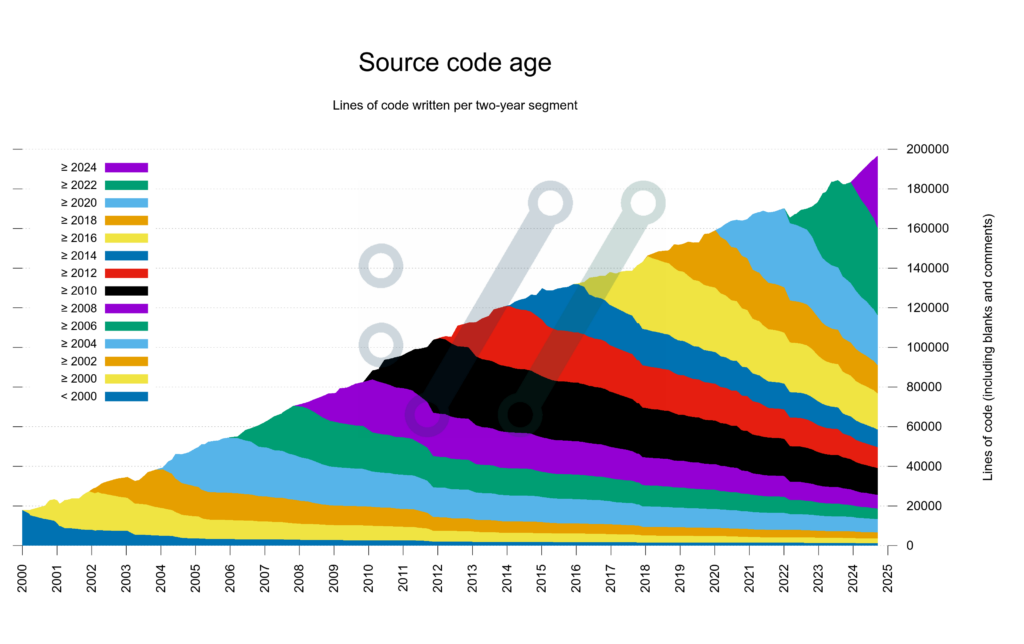
It’s pretty much impossible to miss the big push to use AI/LLM (Large Language Model) coding assistants for software engineers. Individual engineers, small and large companies seem to be going “all in” on this1. I’m generally wary of things that are this popular, as those often turn out more cargo cult than genuinely positive. So what’s a prudent thing to do as a software engineer? I believe the way ahead is a boring piece of advice, taht applies almost everywhere: instead of going easy, do more of the difficult stuff.
I genuinely think that putting the AI/LLM genie back into the bottle is unlikely (the same way as some people want the Internet, or smartphones, or cryptocurrencies put back into the bottle, which also not really gonna happen). That doesn’t mean that uncritical acceptance of the coding assistant tools should be the norm, au contraire, just like any tool, one needs to discover when they are fit for for the job, and when they are not. I have used GitHub CoPilot for a while, now digging into Cursor as it starts to conquer the workplace, and ChatGPT & Claude for individual coding questions. I don’t think it’s controversial to say that all these tools have their “strengths and weaknesses”, and that currently the more complex, more “production” the problem is, the further away it is from a proof-of-concept, the less likely these tools are of any help. They are help, they can be a large force multiplier, but they are big multiplier when one goes in with the least amount of input (knowledge, awailable time, reqirements for the result…)